Ever wanted to setup a parallel environment to simulate or test cloud computing but didn’t want the headache? One great alternative is to use IPython Parallel.
It’s easy to use and in no time you can have a scalable cloud computing environment with very little setup or headache.
Installation
First the basics. Install IPython along with its parallel dependencies:
pyzmqfor job queue managment and communication. Version 2.x.x ONLYIPython.parallel(obviously)
You’ll probably find this page helpful.
Starting the Ipcluster
IPython Parallel has the following actors:
- Controller
- Engine
- Client
Let’s see how to use them. Open up three terminals. In the first, run:
$ ipcontroller
Then in the next two, run:
$ ipengine
Great, you just started a coordinator (a “controller”) and two workers (or “engines”).
Now let’s actually do something with them. Open up yet a fourth terminal, and do the following:
$ ipython
Then run:
In [1]: from IPython.parallel import Client
In [2]: engines = Client()
We’ve now connected to the Controller and created a handle on our engines in the form of a Client. Let’s make sure that the Ipcontroller sees our Engines:
In [3]: engines.ids
Out[3]: [0, 1]
Great. Now let’s try looking at just one:
In [4]: engines[0]
Out[4]: <DirectView 0>
What’s great is that we can address each Engine separately if we want to. We can also address the whole compute cloud as a load balanced cloud, as we’ll see later.
Direct Views
The simplest way to do a task is to simply as a single Engine to perform it using a Direct View.
In [4]: engines[0]
Out[4]: <DirectView 0>
Roughly, the system looks like this:
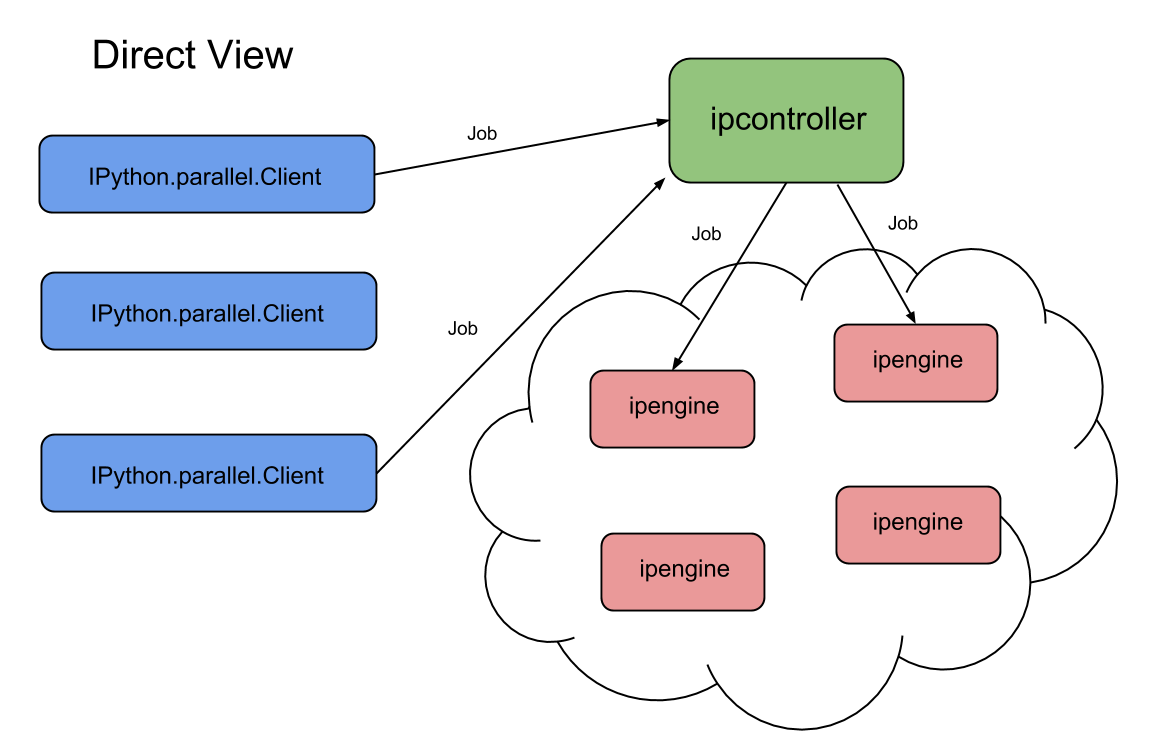
We send tasks one at a time to a specified Engine, and recieve the result in the same way.
Let’s define a simple task, say, squaring a number:
In [5]: def square(n):
...: return n**2
...:
Now let’s tell our first engine to run it using apply():
In [6]: answer = engines[0].apply(square, 8)
What’s great about the framework is that the answer we get is actually designed for asynchronous calls:
In [7]: answer
Out[7]: <AsyncResult: square>
Here, squaring a number is a simple task that probably finishes in a few milliseconds, but if it was instead processing images or training models, we probably want to do other things while that process is thinking.
You can check an AsyncResult at any time to see if it is done:
In [8]: answer.ready()
Out[8]: False
False means don’t touch it yet. When it is ready, however, we can retrieve the result:
In [8]: answer.ready()
Out[8]: True
In [9]: answer.result
Out[9]: 64
You could also pass block=True to apply() and you could do your computation synchronously, but that would defeat the purpose of using mutliple processes most of the time.
Importing modules directly
We can also import modules on all the engines at the same time:
In [10]: with engines[:].sync_imports():
....: import random
....: import time
....:
importing random on engine(s)
importing time on engine(s)
Load Balanced View
If you want to abstract away how many Engines you actually have and just treat your cloud as a workhorse, you may want to use a load balancer.
In [11]: balancer = engines.load_balanced_view()
In [12]: balancer
Out[12]: <LoadBalancedView None>
In [13]: balancer.block = False
Here we’ve created a load balancer and made sure it works asynchronously.
The system looks something like this now:
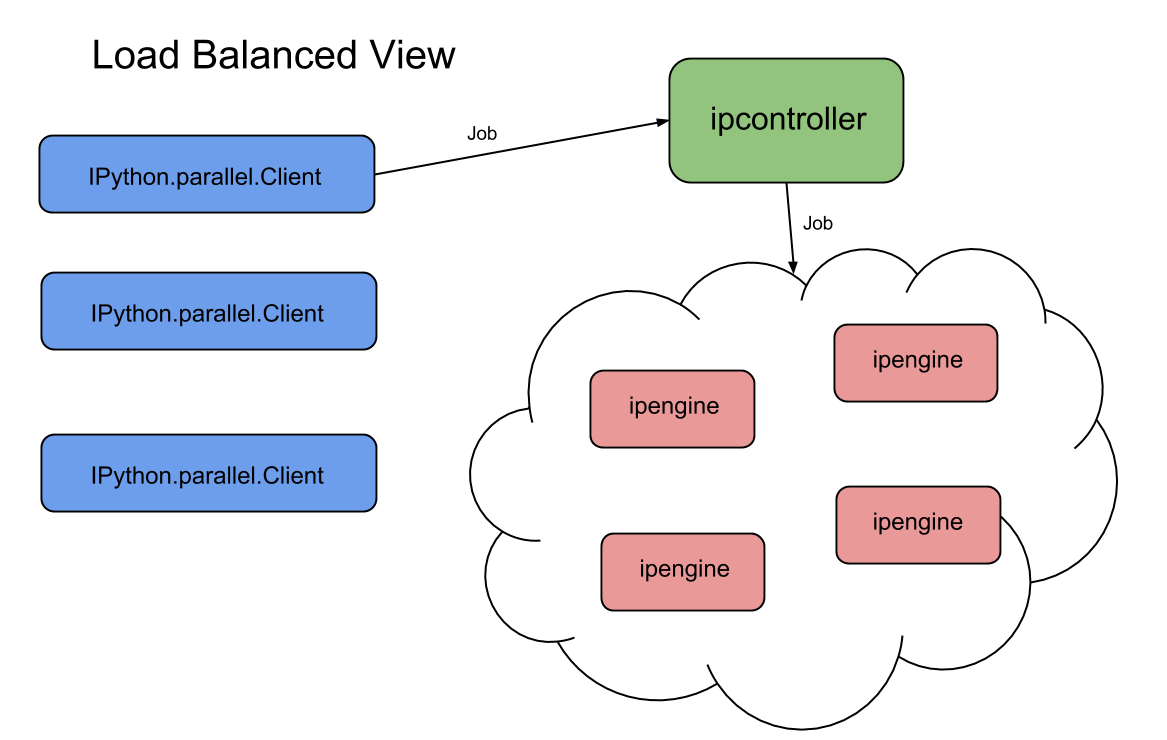
Now let’s compute the squares of the numbers in the range [0, 25], but make sure that each function call is computed as soon as there are resources in load balanced fashion.
Let’s define a new square function to simulate network unpredictabilities:
def square(n):
import random, time
time.sleep(random.randint(0, n/6))
return n**2
We’ll also make use of the balancer.map() function, which allows us to apply many jobs to a load balancer at once.
Here’s the script:
from IPython import parallel
import time, random
LOOP_WAIT = 1
# worker function
def square(n):
import random, time
time.sleep(random.randint(0, n/6))
return n**2
# tasks and client nodes
print 'Creating jobs...'
jobs = range(25)
random.shuffle(jobs)
engines = parallel.Client()
balancer = engines.load_balanced_view()
balancer.block = False
results = balancer.map(square, jobs)
while not results.ready():
time.sleep(LOOP_WAIT)
print "Results ready!"
print [x for x in results]
This script will wait until all jobs are finished to print out the answers, but will complete the jobs as engines finish as quickly as possible.
Let’s run the script:
$ load_test.py
Creating jobs...
Results ready!
[324, 64, 121, 225, 484, 9, 256, 0, 529, 81, 144, 25, 36, 196, 4, 100, 289, 576, 1, 361, 400, 49, 169, 16, 441]
Works great!
Dependencies
What if we wanted to have two jobs run, but one specifically after another?
From our code above, we can add something like this:
harder_jobs = range(50)
with balancer.temp_flags(after=[results]):
harder_results = balancer.map(square, harder_jobs)
Here’s the script:
from IPython import parallel
import time, random
LOOP_WAIT = 1
# worker function
def square(n):
import random, time
time.sleep(random.randint(0, n/6))
return n**2
# tasks and client nodes
print 'Creating jobs...'
jobs = range(25)
random.shuffle(jobs)
clients = parallel.Client()
balancer = clients.load_balanced_view()
balancer.block = False
results = balancer.map(square, jobs)
harder_jobs = range(50)
with balancer.temp_flags(after=[results]):
harder_results = balancer.map(square, harder_jobs)
while not results.ready():
time.sleep(LOOP_WAIT)
print "Results ready!"
print [x for x in results]
while not harder_results.ready():
time.sleep(LOOP_WAIT)
print "Harder results ready!"
print [x for x in harder_results]
This one prints:
$ load_test_dependencies.py
Creating jobs...
Results ready!
[324, 64, 121, 225, 484, 9, 256, 0, 529, 81, 144, 25, 36, 196, 4, 100, 289, 576, 1, 361, 400, 49, 169, 16, 441]
Harder results ready!
[225, 2025, 1156, 529, 4, 441, 81, 36, 1764, 1296, 729, 841, 1936, 2209, 676, 1444, 121, 324, 9, 961, 100, 2304, 196, 1681, 1521, 16, 1369, 484, 144, 256, 1, 25, 784, 576, 169, 1225, 2116, 289, 400, 625, 900, 64, 1849, 1600, 0, 1024, 49, 2401, 1089, 361]
Conclusion
IPython parallel is a great framework, it’s easy to use and painless to set up. For a more in depth tutorial, see here.