Music AI state of the union: an ISMIR '24 summary

ISMIR ‘24 (the conference for the International Society for Music Information Retrieval) this year was fantastic. I had an absolute blast getting to meet up with the brightest minds in the music AI space.
The pace of innovation in music AI is absolutely breathtaking.
For this post I chose a few themes I noticed at the conference. In each section I’ll describe my favorite paper and mention a few other papers to check out. You can see a full list of ISMIR ‘24 papers here.
Finally, if you’re in the music AI space and want to be friends or grab a coffee, hit me up on twitter or shoot me a message!
I’m currently working on a new stealth project building realtime models that make audioreactive light shows like Coachella possible – a perfect fit for ISMIR.
Theme #1: Latent spaces - discrete and continuous
A recent trend in audio is training better latent space representations. They help with both compression and generation tasks. The two are somewhat related — audio is an extremely information dense modality, and bottlenecking information is playing out much like we saw in the image world once diffusion started happening in latent space rather than pixel space.
Neural codecs using RVQ (ie: Encodec, DAC) or continuous autoencoders are the two preferred types of information bottlenecks today.
Codecs are better at high quality reconstruction and phase coherence, but reconstruction falls apart if you shift them in time. The codebook vectors also can be used as discrete tokens, or the last layer before the quantization can also be used as a continuous latent.
Continuous latents are wonderful for downstream tasks and are quite good at capturing lower frequency or harmonic components, though often at the expense of phase when decoded.
My favorite ISMIR ‘24 paper on this theme was:
📚 Music2Latent: Consistency Autoencoders for Latent Audio Compression [paper] [github], the PhD work of Marco Pasini in partnership with Sony Paris.
Music2Latent broke the mold of difficult-to-train audio autoencoders (no GAN!) and trains with a single loss term. Most interestingly, as Marco revealed in the poster session, if one takes two latent embeddings from Music2Latent and interpolates between them and then decodes, you get audio that sounds like the two original waveforms mixed together in equal proportion. Extremely cool, and a huge step forward for a better latent space forgenerative models.
The only dissapointing part is that the model will not be released, and that the code is under CC BY-NC 4.0 :/ but the code is on Github!
Other noteworthy papers:
- Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation
- An excellent example of a hybrid appraoch using Encodec:
"...we use the continuous tensor z as the latent representation, while leveraging the discrete representation q for audio conditioning."
- An excellent example of a hybrid appraoch using Encodec:
- Audio Conditioning for Music Generation via Discrete Bottleneck Features
- This is another FAIR paper, and so they also use Encodec, but as tokens in an autoregressive model
Theme #2: Diffusion for audio generation
Increasingly diffusion is being used for audio generation. It has a few nice properties:
- Inference can happen in parallel (not autoregressive)
- We can borrow a lot of techniques from image diffusion generation
- We don’t have to think about tokenization
The star paper here for me was another from both Sony and Queen Mary University of London:
📚 Diff-A-Riff: Musical Accompaniment Co-creation via Latent Diffusion Models [paper].
And coincidentally, it was trained using Music2Latent! So this is a nice segue from the last theme.
First off, the Diff-A-Riff generation quality is incredible. Take a listen for yourself.
Diff-A-Riff generates audio, conditioned by other stems, to create a target stem (the “accompaniment”). So you give it a guitar and a bass line and tell it to create a drum stem of the same length, and it will. You can even guide the accompaniment creation by conditioning with either an audio snippet or a text prompt.
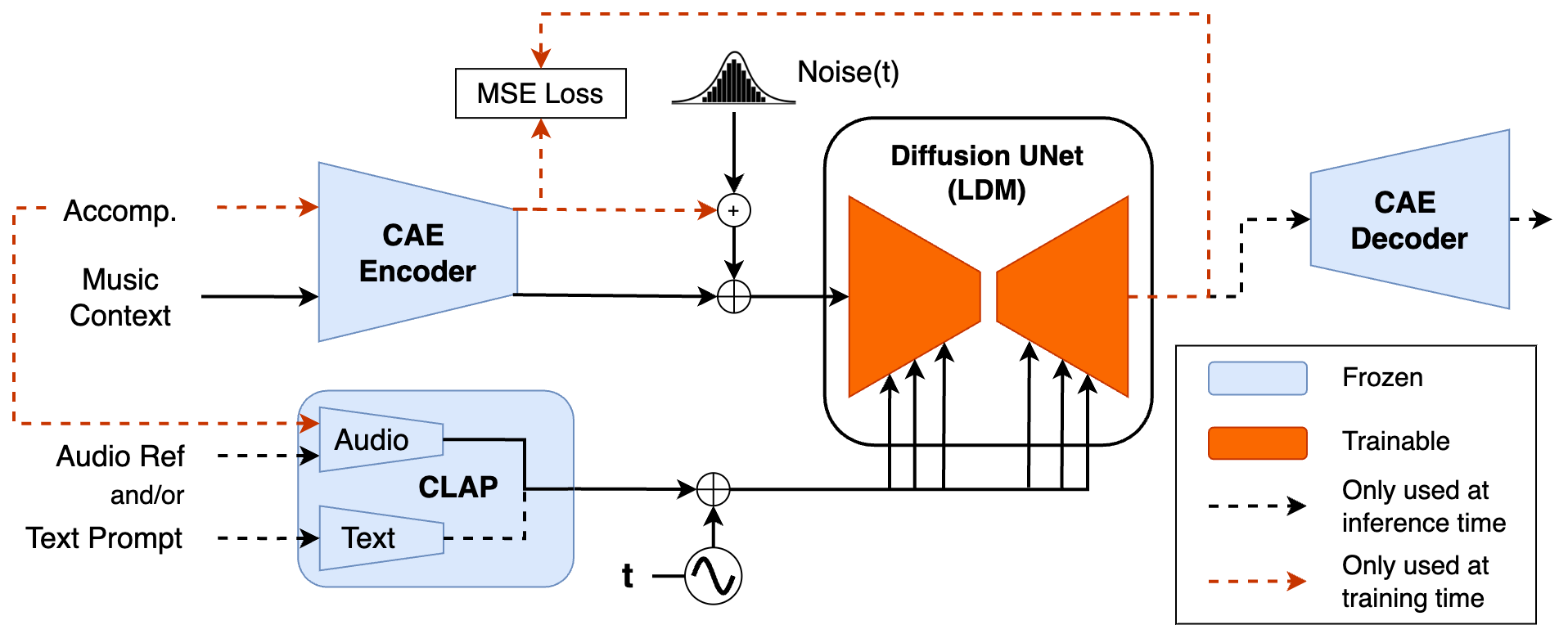
As you might expect CLAP is used to achieve a shared text-audio space, but they have several other clever ways of handling the conditioning. Though the code and models will not be open sourced, it’s a really fascinating paper and some stellar work by the Sony Paris team.
Back on theme, while it’s tempting to say that diffusion looks like the winning approach for audio generation I don’t think we can quite be sure.
We know Suno uses an autoregressive architecture (at least in v2-3) (see this podcast with their CTO, Mikey Shulman), and their generation quality is the best in the world for full-length tracks. And I don’t actually know what Udio uses, but if you do let me know!
Other noteworthy papers:
- Long-form music generation with latent diffusion (Stable Audio paper)
- Combining audio control and style transfer using latent diffusion
- Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation (this one uses flow matching, but it’s just a great paper)
Theme #3: Self-supervised learning (SSL) techniques gaining steam
Across a number of tasks like beat tracking, stem-affinity, and tonalty estimation, self-supervised learning (SSL) techniques started to shine this year at ISMIR.
These techniques are especially important in the music space where labeled data is far more limited than in the text, image, or video domains.
Favorite SSL paper:
📚 Stem-JEPA: A Joint-Embedding Predictive Architecture for Musical Stem Compatibility Estimation [paper] [github] by Alain Riou et al, from Institut Polytechnique de Paris and Sony.
Basically the jist here, is that given a few stems aligned in time, you can train a model to output the latent representation of yet another stem that best fits the existing stem mixture (and any given conditioning signals you supply).
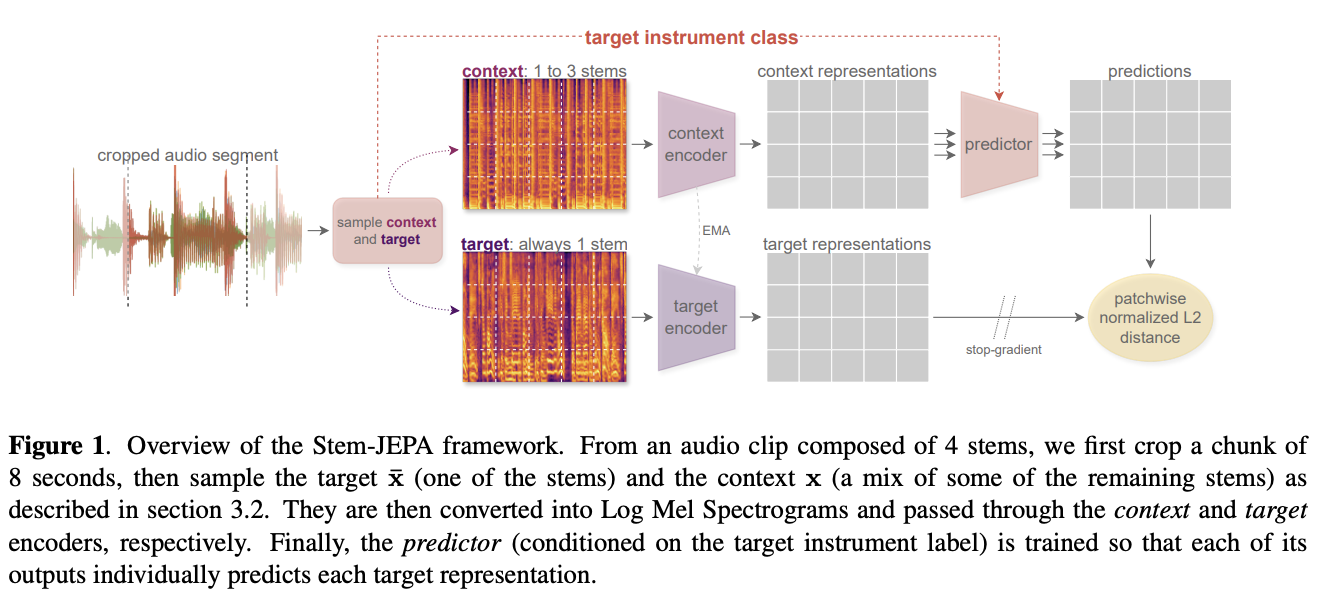
So, why is this nice?
Well, if you want to generate, say a bassline for your jazzy vocal, what are your options?
- Manually swap in and out stems, listening for compatibility
- Time consuming
- Generate the missing stem
- Expensive FLOPS-wise
- Requires you to have such a generative model in the first place with extremely high quality
- You’d still need to score the generated stem against your existing stems to make sure it’s compatible, or have a model that uses the existing mix stems as conditioning
- Train some sort of model to score your existing stems for compatibility
- Expensive computationally – we’d have to score each existing stem in your database against your currently active stem mixture to calculate a ranking by score
The JEPA approach here let’s us instead generate the “idea” of which kind of stem would fit best.
With this, we can then query a database of stems (with precomputed JEPA embeddings) to find which are the most compatible, using a simple nearest-neighbor approach. This does require one to precompute all the embeddings for the stems in your dataset, but that’s easily done ahead of time. At inference time, the JEPA system can be much faster. For that reason, Stem-JEPA is a wonderfully clever piece of work.
A downside: when training, Stem-JEPA does require split stems (which are less plentiful in the world than mixed audio). Luckily, it appears this model is quite data efficient!
With ~100x less data, downstream tasks using this learned embedding space are on par with representations generated with MULE (trained on 117k hours) and Jukebox (1.7M songs). Stem-JEPA was trained on Sony’s 20k multitracks (only ~1,350 hours by comparison).
A few other papers I enjoyed in the self-supervised realm at ISMIR ‘24:
- STONE: Self-supervised Tonality Estimator
- SKY: Self-supervised Learning of Major and Minor Keys from Audio
- A Contrastive Self-Supervised Learning scheme for beat tracking amenable to few-shot learning
Theme #4: Music stem separation (MSS): separation by query
We’re all familiar with the traditional Vocals, Drums, Bass & Other (VDBO) separation — you input an audio mix, and a model like Demucs or RoFormer outputs an estimate of each of this fixed set stems.
Today fine-tuned, offline, single-stem MSS extraction models can be in the range of ~8-12 dB SDR when compared with the ground truth stems, which is very impressive.
However offline SDR gains on those fronts are diminishing returns and increasingly, the field is moving towards:
- Extracting a larger set of stems (ie: piano, acoustic guitar, electric guitar)
- Extracting a stem by a text or audio “query”
- Making the separation process more efficient
Realtime MSS is a different story (largely ignored at ISMIR ‘24), and you can contact me if you want to chat about this :)
But for the offline MSS theme, my favorite paper was led by the indomitable Karn Watcharasupat, who has a number of papers on this topic.
📚 A Stem-Agnostic Single-Decoder System for Music Source Separation Beyond Four Stems [paper] [github].
Their Banquet model architecture lets you train effectively infinite “decoders” for different stems. These decoders are simply a FiLM query embedding that you pair with a known, fixed stem type.
The benefit of course, is that unlike other architectures, your number of parameters dedicated to decoding a single stem drastically decreases from millions down to a few hundred, the cost of a single vector!
So in the last step of the model at inference time, you use the FiLM query vector to extract the stem you’re after – a sort of latent space “mask”.
Even better, there’s nothing inherently keeping the query set (and therefore the stems that are extractable) fixed. In their paper, the FiLM query vector set was, in fact, frozen per stem due to training instability, but it feels like a similar architecture could support arbitrary embeddings being used to extract arbitrarystems. This is the next frontier of MSS in my opinion.
Being able to query a mix for a bass guitar, for example, using an audio snippet of a similar stem (or an isolated snippet of said bass guitar from another part of the track) feels like the correct UI for MSS to extract the exact stem you’re after.
As a final note, MSS is close to my heart as the area I work most heavily in. At VJ Labs we work (among other realtime techniques) on realtime MSS — something which we proudly surpass the SOTA in :) But alas! No papers about realtime MSS this year at ISMIR!
Other stem separation (MSS) related papers from this year’s ISMIR:
- Mel-RoFormer for Vocal Separation and Vocal Melody Transcription
- Notewise Evaluation of Source Separation: A Case Study For Separated Piano Tracks
- Classical Guitar Duet Separation using GuitarDuets - a Dataset of Real and Synthesized Guitar Recordings
Theme #5: Better transcription data, better transcription models
While of course models are getting better, largely the transcription fight seems like it’s being won on the data front, both natural and synthetic.
My favorite paper in this space was undoubtedly for guitar transcription:
📚 GAPS: A Large and Diverse Classical Guitar Dataset and Benchmark Transcription Model [paper], from first authors Xavier Riley & Nicolas Guo from C4DM.
I highly encourage you to watch the video showing the played vs transcribed MIDI side by side. The results are stunning.

Piano transcription datasets (MAESTRO, MAPS, etc) are much larger, today. So Xavier & team created their own dataset and used it to fine-tune a piano transcription model from Bytedance.
Transcription data pipelines are no joke (extensive alignment and quality checking), so even though the dataset is on the smaller side, it’s quite impressive that ~14 hours of guitar was so effective.
Notably, the model is a “simple” (ie: non-Transformer) CRNN (log mel frontend + convolutional features + bidirectional RNN) operating at roughly 10ms granularity.
Other transcription papers:
- Leveraging Unlabeled Data to Improve Automatic Guitar Tablature Transcription
- Semi-Supervised Piano Transcription Using Pseudo-Labeling Techniques
- A Method for MIDI Velocity Estimation for Piano Performance by a U-Net with Attention and FiLM
Theme #6: Attribution
Having a trail of provenance for which music samples, ideas, models, or styles inspired or created a given piece of music was also clearly a theme at this year’s ISMIR, though more so in conversations and panels than papers.
As you might imagine, there’s a huge storm coming in terms of the rights holders of the world (record labels, copyright holders, artists) wanting their piece of the generative AI pie.
The big questions fall at the input and output:
- ➡️ On the input side: is training models on copyrighted audio “fair use”?
- ⬅️ On the output side: by what metric is a new piece of audio deemed to “copy” another, and to what extent?
To be fair, papers aren’t the place to tackle these issues. Likely the US Supreme Court will have that honor. But the various technical approaches being explored reflect these thorny issues.
The only paper really worth mentioning was:
📚 Exploring Musical Roots: Applying Audio Embeddings to Empower Influence Attribution for a Generative Music Model [paper] [examples]
The paper basically amounts to “fingerprinting” a dataset of audio using CLAP and CLMR embeddings, and then querying a dataset of music with these fingerprints nearest-neighbor style, and seeing how similar the retrieved audio was to the originally embedded query audio.
Largely if you listen to the examples (or just think about what’s being done) it’s clear that this is not a good approach.
This falls on the “output” side of the attribution question. And querying based on feel or vibe (basically what CLAP and CLMR are good at) is just going to return matches that are of a similar style or genre, not musical infringement.
To me, the more sensible approaches center around a couple of “output”-based infringments:
- Sampling (copying audio)
- “Did the artist literally copy and paste another piece of audio?”
- Spectral (traditional) audio fingerprinting is a much better approach here, with far less computation, less learnable parameters, and far lower false positives
- Structural similarity (copying structure)
- “Did the artist directly rip off the chords or melody or lyrics?”
- This likely is solved technically with transcription models and some kind of MIDI similarity metric
For either approach, the thorny issue still is “to what extent” is a piece of music considered to be a copy? And if such a determination is made, what are the monetary and access consequences for the creators, the original rights holders, and the public?
This line of thinking merits an entire post (or book) of its own, so I’ll stop here.
Interested readers, artists, or music AI researchers should check out my favorite book on the subject: Free Culture by the famous Lawrence Lessig, founder of Creative Commons (yes, that one!). It’s an indispensable read.
Summary
ISMIR ‘24 was a blast. I’m already looking forward to next year!
See you all in Korea in ‘25 🇰🇷