Who's Getting Leaked? Analyzing 1.2 billion leaked user credentials
Data breaches are happening more frequently than ever before. We’re all downloading more apps, buying more things online, sharing more with more people, and overall, generating a larger online footprint. Not surprisingly, this means a larger attack surface, and data leaks are only going to get more frequent.
How easy is it to get a hold of this data? I delved into the dark corners of the web and was able to download roughly ~1.2 billion unique user credentials. This includes mostly emails and password/hashes, but often phone numbers, gender, addresses, and sometimes even SSNs and credit card numbers.
Terrifying.
First, I’ll give some background on breaches and the movitations around them.
Next, I’ll show some analysis on roughly 225GB of pure user data in Python and try to understand how this web of data breaches looks at a large scale.
Finally, I’ll talk about the future - areas of growth and large markets for entreprenuers and investors.
What got me looking: the Equifax breach
When news broke that Equifax, the credit rating agency, had been hacked and lost upwards of 143 million user credentials, including names, birthdates, social security numbers, and credit card numbers, people were upset. Probably not upset enough, honestly.
We’ve grown desensitized to data breaches and what could happen to our personal information, credit, and even our identity once critical data is exposed. The US Department of Justice (DOJ) found in 2014 study that Americans loose on average $15.4 billion USD to identity theft. That number is accelerating.
Equifax’s response was to tweet links to phishing scams and require people to input their SSNs to their system to see if they got hacked.
But don’t worry, Equifax understands what it’s like (search done Sept 27th, 2017):
Probably that threat of emotion turmoil was what caused Equifax executives to dump about two million USD worth of shares before the hack was announced and the stock plunged:
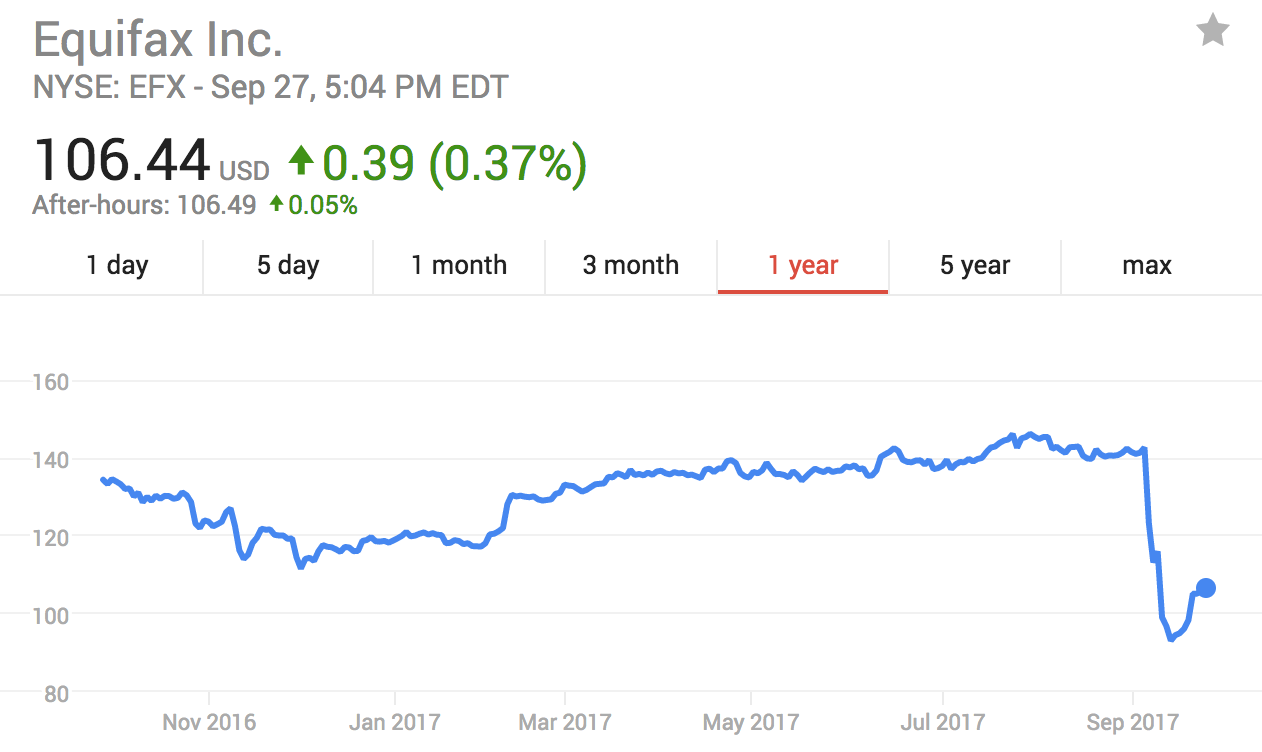
Yuck. And these are the people determining who gets loans on what terms?
Just the tip of the iceberg
There are far more data leaks, Equifax is just one of many.
Other organizations hit by hacks: Avast, Dropbox, Elance/Upwork, Linkedin, MySpace, Ashley Madison, Target, Yahoo, Neopets, Patreon, Twitter, Tumblr, and many others.
Even the US government isn’t immune: 191 million voter records were found to be publically exposed, and the FBI employee database was hacked as well.
So what’s driving these breaches?
The black market for data
While some leaks are politically/morally motivated and less about technical exploits (Snowden’s NSA leaks, the Panama Papers, or Big Tobacco lying about nicotine levels), most appear to be for their straightforward transactional value on the black market.
A database leak of credit card information, for example, has an average value per record that scammers or fraudsters can buy online and use this to steal identities, apply for credit cards, and otherwise fraudulently get more money on average per record than they paid for it. The average price for qualified credit card info is about $30-40 per record, bank numbers are around $300, and healthcare documents and associated documents can be as much as $1,000. There’s terrifying table of costs here if you’re interested.
So you can do the math: a leak of even 1 million credit cards is worth a lot of money. If you’re just a cyberhacker in Ukraine (or anywhere, really), that’s a life-changing amount of money, even if you only collect a small portion of it.
In Russia alone, it’s apparently a $680mm market, with over half of the payments by volume from 2011-2014 being made in cryptocurrencies.
This financial incentive, however, also leads to fabricated leaks. The zoosk (a dating site) “breach” was likely suspected to be a mostly-fake mismash of accounts from other leaks, a conclusion of some detective work by data breach whisperer Troy Hunt. A similar occurence happened with a large email “leak” from mail.ru where most of the credentials turned out to be invalid.
Milder leaks, like email/password hash dumps (like Linkedin hack) still have inherent value. Once the hashes are cracked, not only do hackers get access to accounts, but many folks use the same passwords on other services. Spammers, people who sell shares / likes / messaging, and other shady folks are all potential buyers. Here the pricing goes quite low, around $0.001 per account, and probably free if you know where to look or have the right friends. Most database dumps are freely available if you wait long enough.
Even the hash dumps themselves are useful in building up rainbow tables and finding clues to steal more valuable accounts. Application developers out there: salt your passwords!
A new variant on this is ransomware. Here, the “customer” is the person (or company) who owns the data, and would rather not have it be destroyed or released. Essentially you either pay up on time to an anonymous bitcoin wallet and you get your data back, or you don’t, aaaaaand

However, stolen data, unlike wine, declines in price with age.
The half-life of stolen data
Data like this is only really valuable as long as you’re among the first the have it. Or better yet, that no one knows about the breach (though this is rarer). It might be that Bank of America was hacked years ago, and that hackers are still siphoning off money - we just don’t know.
Once the first buyers hit the market and start doing their own prospecting, they’ll sell the scraps the the next folks, and so on. I don’t have any insight into this process or how long it takes, but I do know that leaks as late as early 2017 are popping up in public dumps or torrenting sites.
There’s also a fairly thorough (but not sophisticated) trading market in place for people that just like (for whatever reason) collecting the data for non-nefarious purposes. I admit I fall a little into that category, or you wouldn’t be reading this. Trading happens simply to get databases they don’t have. Because you’ve gotta catch ’em all.
It took me about a week of searching before I called it “good enough” with a little over 2 billion unique records (analysis below is for a subset of ~1.2 billion of those) - I had proved my point. But before I wiped all the data, I was curious to find in a little more detail what this data looked like.
What’s the data look like?
The small sample I managed to collect was about 225GB of pure user data on about ~1.2 billion unique user credentials. The data formats were mostly CSVs or SQL dumps of various types.
First off, here’s a sampling of a few of the breaches:
- Experian / T-Mobile (26 million):
email,fullname,address,ethnicity,gender,income,home ownership,ip,purchasing records - MySpace (359 million):
email,password - Strafor (900k):
email,password,fullnames,credit card,address - Adobe (150 million):
email,password,password hints - Badoo (110 million):
email,password,birthdate,gender - Modern Business Solutions (57 million):
email,password,ip,name,address,gender,job title,birthdate,phone - Exploit.in (589 million):
email,password - Ashley Madison (30 million):
emails,passwords,ethnicity,gender,sexual orientation,sexual desires,fullname,phone,payment information - Adult Friend Finder (3.6 million):
email,fullname,ethnicity,gender,sexual orientation,ip - Mate1 (26 million):
emails,passwords,sexual desires,income - Dropbox (67 million):
email,password - Texas Voter Database (655k):
fullname,address,previous addresses,birthdate,gender,phone,legal status - Florida Voter Database (12 million):
fullname,address,previous addresses,birthdate,gender,phone,legal status - Colorado Voter Database (3.5 million):
fullname,address,previous addresses,birthdate,gender,phone,legal status - VK (91 million):
emails,passwords,phone
And many more.
Some, like the FBI leak / other government leaks / anything with SSNs I verified but immediately deleted. I don’t want to be anywhere near that.
What was the distribution of domains across leaks?
I was curious about the distribution of users’ email domains and their correlation to the sites themsevles.
First, let’s see what the overall distribution looks like.
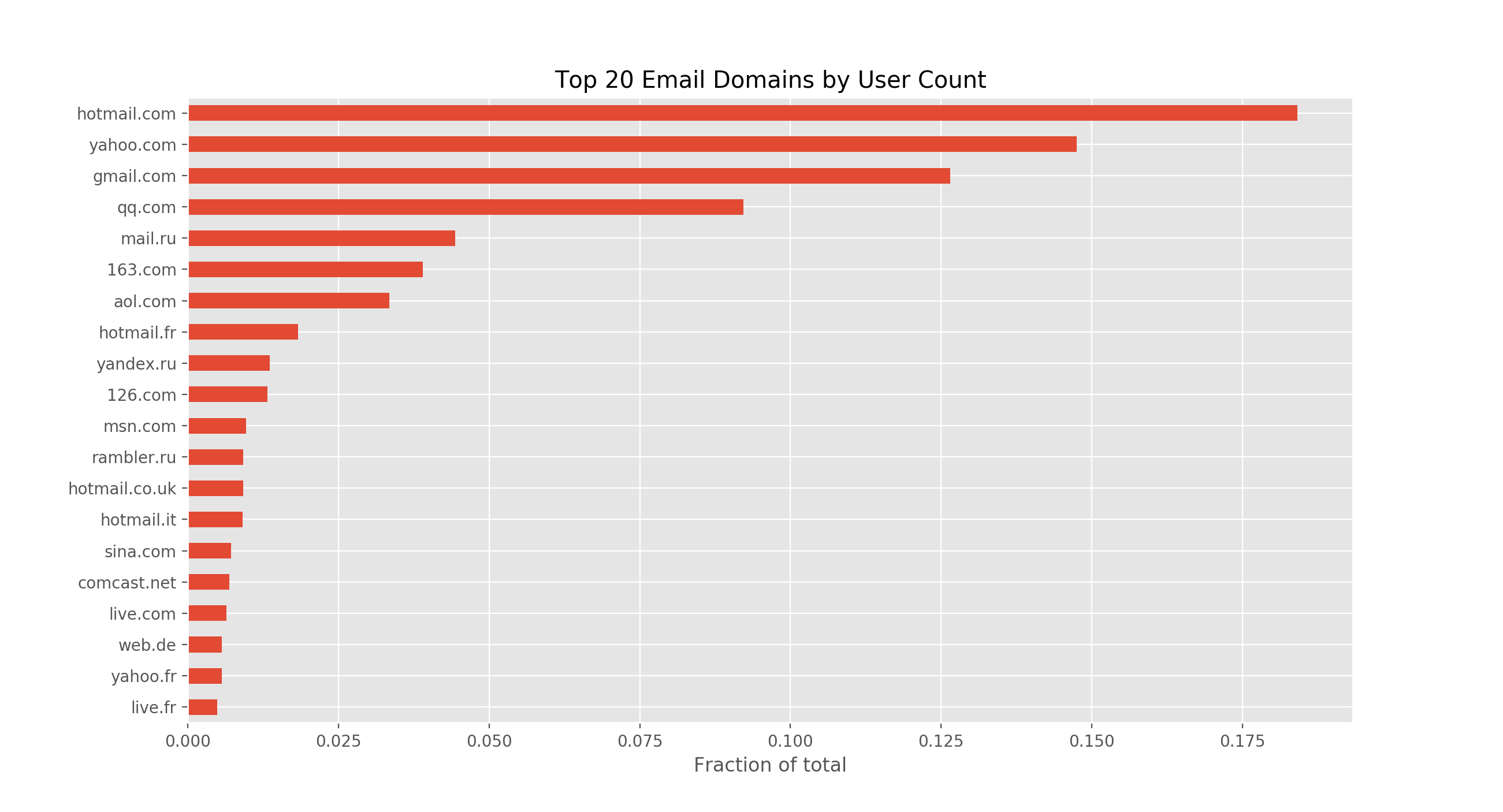
Over half the email accounts are from the top four providers: Hotmail, Yahoo, Gmail, and QQ. I suspect Gmail’s lag here is due to the fact that these leaks are a few years old. As we’ll see below that distribution starts to shift in more recent leaks.
Now let’s segment by leak, and see if there are any interesting patterns.
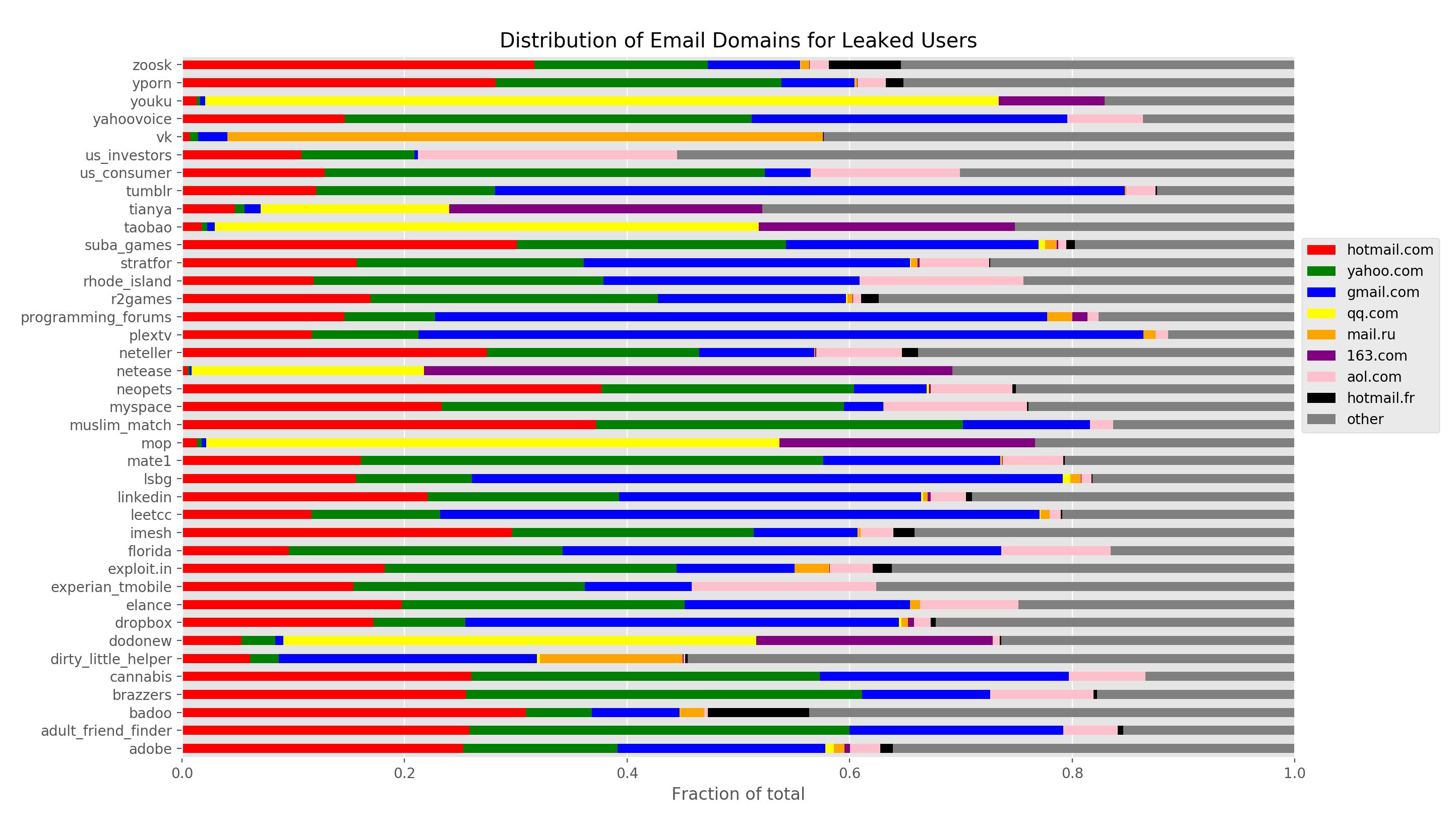
There’s obvious patterns like high mail.ru usage among vk users and high qq.com and 163.com among all the Chinese leaks like taobao, youku, and dodonew.
For other leaks, though, it’s all sorts of fun to go down this list and invent fun theories why the distribution is the way it is.
US investors having a huge skew to aol.com email addresses seems quite plausible: older, more conservative, more affluent Americans who got an email address early and stuck with it, perhaps?
plextv, tumblr, and programming_forums have unusually high Gmail ratios - the result of younger folks, more recent dumps, or folks that don’t like to pay for their entertainment or software? :)
dirty_little_helper, the gaming cliffnotes site, has an large mail.ru component. Perhaps gaming is more popular in Russia? Or maybe cheating on games is disproportiate there…
User overlap?
Even more interesting, I was curious what overlap in users different services had. I assumed (somewhat correctly) the largest overlap would be in the “adult” category of sites, so I decided to find out.
Essentially each edge is the average percentage overlap bewteen the two, so given two breach email sets: $B_i$ and $B_j$, the edge score $e_{i,j}$ is the average ratio between the two:
$$e_{i,j} = \frac{ \frac{| B_i \cap , B_j | }{ |B_i| } + \frac{ | B_i \cap , B_j | }{ |B_j| } }{2}$$
Then to scale relatively I simply min/max scaled by dividing all the edge scores by the greatest - giving us a relative measure of overlap.
Looking at specific leak intersection pairs
Let’s look at overlap between particular datasets, both in terms of our closeness score and absolute counts.
Using our mean intersection as a percentage of total ratio as stated above, we can rank roughly how similar as a percentage of their whole each pair of datasets are.
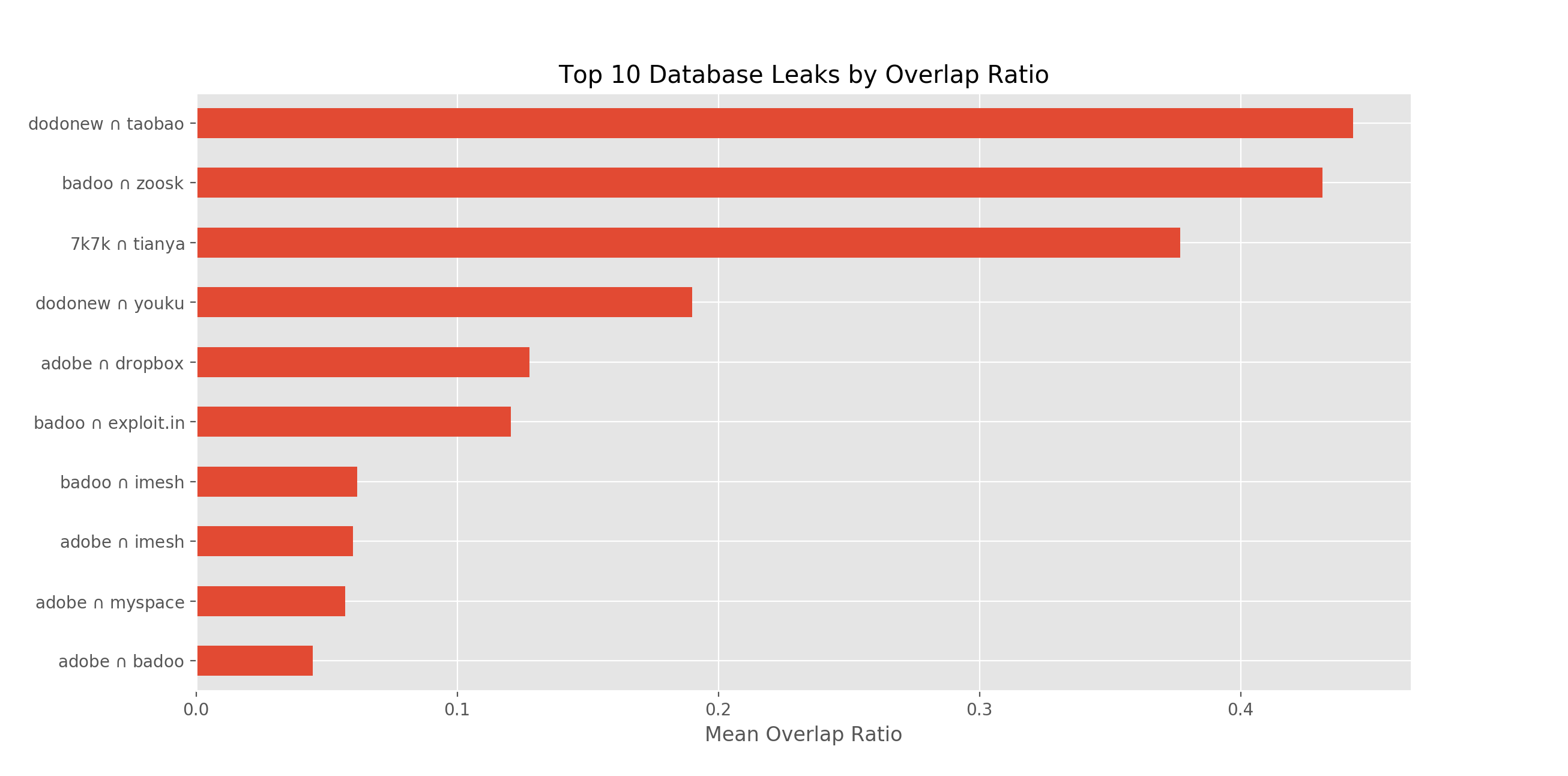
As you can see, near the top are the Chinese leaks in the 1st, 3rd, and 4th spot. Here the 2nd spot (zoosk & badoo) is actually a telltale sign that the zoosk leak was mostly a rip of the badoo leak! Many credentials were “stuffed”, leading to the large overlap. In this way, this type of analysis is extremely useful for sniffing out “fake” leaks which are just repackaging of old ones.
And if you just look at direct intersection count, it’s pretty clear the zoosk leak ripped some from the badoo leak:
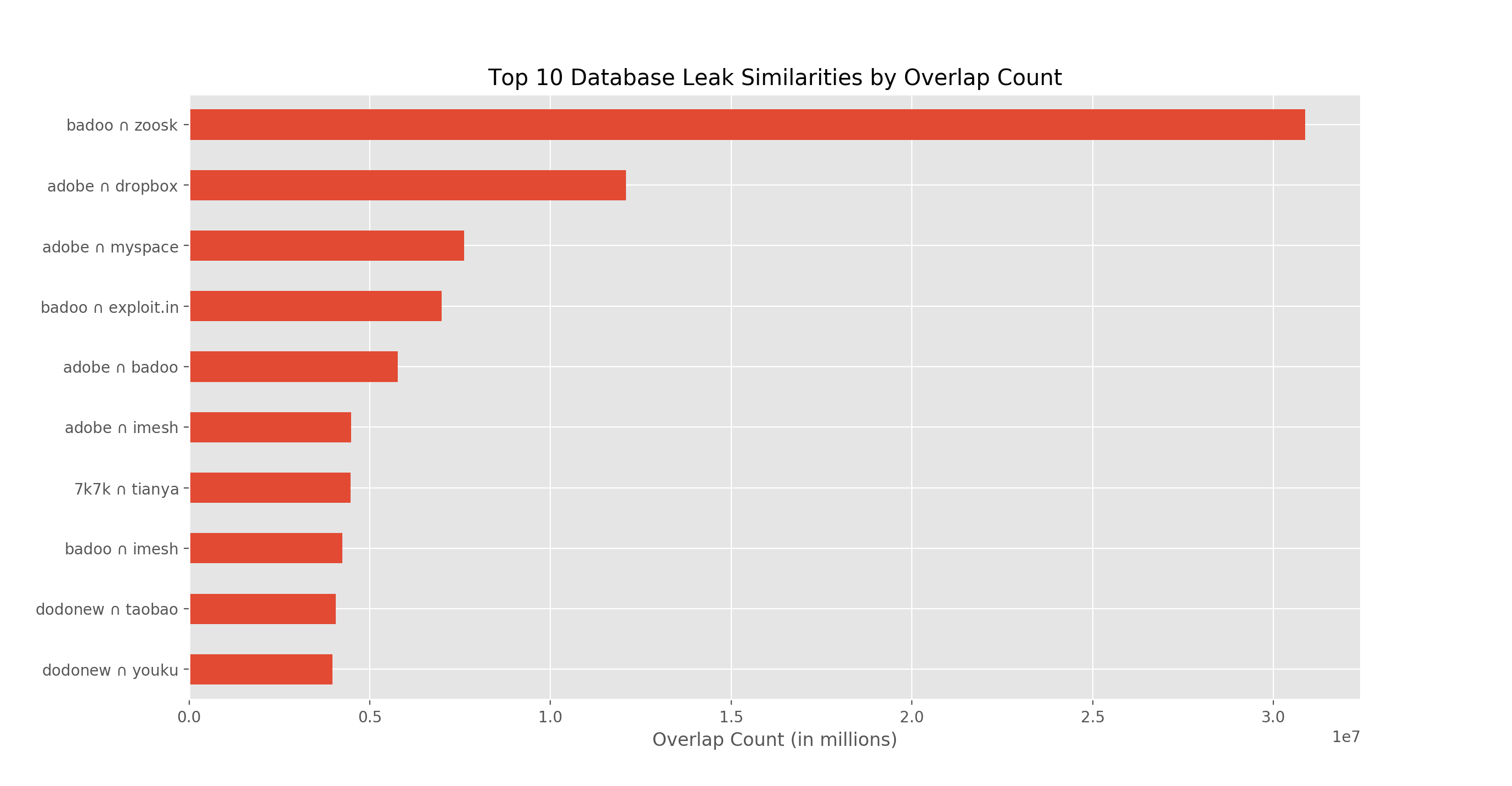
as it and the Badoo leak share over 3 million credentials. To be fair, the zoosk leak was over 50 million credentials, so a further analysis (like Troy’s, mentioned above) was still necessary to certify it as a fake.
There’s a mountain more data and all sort of interesting analysis we could do. And for the harmless, public, or anonymized types of data (public US business locations, passwords without their emails, etc) I may well download those again someday and do some more digging.
How legal is it to anaylze hacked data?
Well it turns out if you even use any of the logins to access those accounts, you’re already in violation of The US Computer Fraud and Abuse Act (CFAA). So if anyone is reading this, please don’t do that.
And certainly no one likes the idea of anyone having their data that shouldn’t. But with some knowledge dissemination to the people who need it, we may be better off educated rather than the alternative. It is my hope this post is part of that process.
As Troy Hunt, a security researcher behind “Have I Been Pwned” (HIBP) notes, we’ve totally lost control of our personal data. Raising that awareness with well thought-out research (that doesn’t expose any personal information to others) is an important service to all of us internet denizens. Troy Hunt & HIBP is probably the most well known and principled example of this. There are other leak aggregators that have accumulated this, but they are for-profit and charge for API access. LeakedSource is one such example, and was shut down (fantastic, CSI-like story on how the original owner was discovered). It’s now back on a .ru TLD.
The main point here is that it’s far too easy. With a few google searches, trawling a few forums, and using a torrent client, billions of peoples’ information is at your fingertips. Add in a reasonable amount of bitcoin, and you’re really off to the races. We should all be a little worried.
This trend should also help to draw attention to existing private information flaws like enumeration attacks. These allow anyone (most often with just a simple “Forgot My Password”) to see who is signed up for a site. In fact, it turns out that even without the hack anyone could find out if you were a member of Ashley Madison .
Their accounts were always public knowledge for those who knew how to look.
The future (and where you should invest)
In the end, I’ve cleared my hard drive but can’t shake the realization of how important security is going to become in the coming years. I’m by no means a security expert, but I do see the writing on the wall.
As one of my wise professors, Nikolai Zeldovich once reminded us, security is a negative goal. It is the never-ending lack of success on the part of the attackers. The attacker only needs to find a single way in, while the defender must prevent a near infinite number of attack vectors. This means as our personal or business’s data footprint gets larger and more distributed, the attack surface is increasing exponentially.
Given this, what seems like good areas of growth:
- Enterprise security devops: More data means more companies with more data. If I run a company with critically sensitive data (bank, insurance, healthcare, etc) I need to know each time some application developer/devops pushes code into (or currently exists in) prod, it shouldn’t have packages with known vunerabilities, errant ports left open, unnecessarily many users credentialed to those backend services, etc. Hackers and nation-states aren’t going to wait around for old companies to figure it out - enterprises are going to have to shape up fast with smart software vendors or get hacked and face the consequences.
- Multiple-factor authentication services: Renders many impersonation attacks obsolete, and a must for businesses. This is already a little crowded, but I think it’s going to be a large market. I think we’re going to see a shift from binary verifications (yes email, yes password, yes SMS => allow login) to probabilistic, risk-based scoring given business goals (14 data points align, geolocation 57% likely, face scan 98%, small value item => let customer purchase item).
- Automated ML-powered pen testing / vunerability monitoring: Pen testing seems to be a pretty high touch service with a lot of social engineering components. Vunerability monitoring often amounts to anomaly detection frameworks which are 99.99% spurious detections - thus warnings go ignored even when things actually go wrong. As a result the buying process centers around compliance and appeasing procurement rather than actual peace of mind. Maybe there are good ways to automate much of that. DARPA has already sponsored automated competitions like this, so there does seem to be promise (although machines autonomously hacking things is also pretty terrifying).
- Hardened, open-source, low-power IoT OS / Hardware: When billions of internet connected things in the wild all have to be running code, it opens up a whole new world of zombie DDoS bot swarms and other security issues. I think we’re going to see an open-source OS emerge in the next few years, perhaps written in Rust, coupled with open hardware designs and extremely strong security gurantees down to the silicon level. The open-source part will be really important to ensure auditability so that our millions of appliances aren’t stealing our data, DDoS’ing our government, or otherwise being nefariously used. I wouldn’t even be surprised if there were eventually US FTC legal mandates/guidelines around it as the cyberterrorism wars start to heat up.
A terrifying thought experiment
Maybe I’ve been putting it too timidly.
What if everyone’s data (email, name, birthdate, address, phone, SSN, credit card) was one day made public? Equifax got us close, but we’re not quite there yet. What would happen to the US? How would we continue to let people buy and sell goods and services?
Given this, other interesting avenues:
- Biometric identification: Can we eliminate false positives & keep false negatives under control? We’re seeing it for consumer (iOS face unlock) / customer service (voice user verification on my Schwab account) usecases now, but transactional offerings or additional factors I think could be useful. We also need to solve the biometric leak problem. It’s easy to change a password if it gets leaked, but a 3D face scan - not so much.
- Cryptocurrency payment services: If we can’t trust credentials, what if we give up trust entirely? Is there a large enough body of legitimate transaction classes that make this a viable alternative for some portion of the everyday layperson’s net worth? Does it confer enough advantages to those same people over cash? I don’t see fiat currency going away, but I also can’t imagine a world in 20 years in which cryptocurrencies aren’t widespread. This 10x as important developing countries. When you live in Zimbabwe and have 500,000,000,000% inflation (yes, really!), Ethereum starts to look pretty stable.
- Blockchain Trust-as-a-Service: what if the most important part of blockchain isn’t value transference or quick transactions, but instead a web of trustless fairness, bonded together only by the laws of economics? Can we incentivize the behaviors, trust, and data sharing that the world needs using codification of contracts and outcomes using trusted, distributed auditors? Essentially trustless prediction markets but at a vast, automated scale instead used for verification and risk scoring. We could close the loop between those who write the scores (credit ratings, insurance underwriters), those who provide the capital, and those who pay (the consumers). This one is a little hand-wavy, but intriguing nonetheless.
Of course all of these have sinister cold-start problems: how do I ensure the person creating a biometric profile or buying crypto is really the same John H. Doe with SSN 123-456-7890?
Incument players have an advantage: if on day X all credit cards get compromised, Amazon (for example) can probably still continue taking payments so long as the browser cookies come from a lineage of known trusted sessions on days < X, the IP address checks out, and the user isn’t buying anything super expensive.
New methods of trust, on the other hand, may not have these crutches and will have to bootstrap this, perhaps from existing services or identities.
The end (of our private data)
In any case, the future is arriving faster than we think and the data is, and will be more and more, in the hands of those we’d rather it didn’t.
Let’s make sure technology can find more ways to mitigate threats than to accelerate them.